우리가 보통 어플리케이션 레벨 기준으로 캐시를 적용한다고 하면 2가지로 나뉜다.
왼쪽 그림과 같은 로컬 캐시와 오른쪽 그림과 같은 글로벌 캐시로 나뉜다.
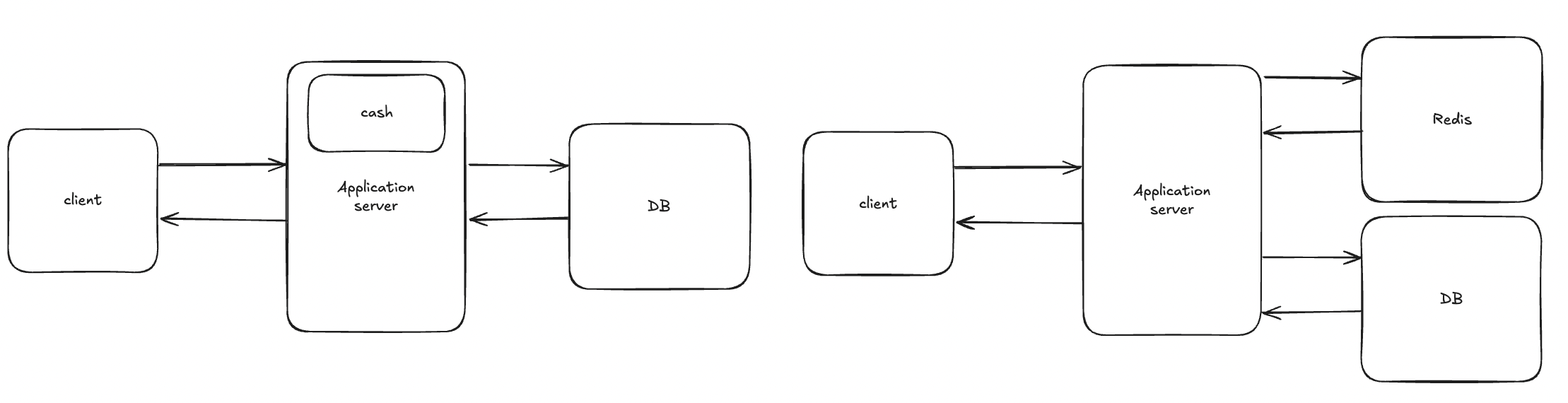
로컬 캐시와 글로벌 캐시는 각각 장, 단점을 가진다.
| 구분 | 로컬 캐시 장점 | 로컬 캐시 단점 | 분산 캐시 장점 | 분산 캐시 단점 |
| 응답속도 | JVM 메모리 직접 접근으로 초저지연 | 인스턴스 당 메모리 제한 (수백 MB~수 GB) | 네트워크 홉이 있지만 여전히 빠른 조회 (ms 단위) | 네트워크 비용·레이턴시(수십~수백 μs) 발생 |
| 일관성 | 단일 인스턴스 내 강력 일관성 | 노드 간 데이터 불일치 가능 | 단일 소스(클러스터)에서 일관성 관리 가능 | 클러스터 복제 지연 시 일시적 불일치 |
| 확장성 | 애플리케이션 인스턴스 늘리면 캐시 미스 증가 | 스케일아웃해도 캐시 데이터 공유되지 않음 | 노드 추가로 무제한 수평 확장 가능 | 클러스터 토폴로지·샤드 재배치 복잡 |
| 장애 범위 | 한 인스턴스 장애 시 해당 노드만 영향 | 인스턴스별 데이터 유실 가능 | 노드 장애 시 자동 페일오버/복제로 가용성 보장 | 전체 클러스터 장애 시 서비스 영향 큼 |
| 운영 난이도 | 라이브러리 설치만으로 빠르게 도입 | 노드별 메모리 튜닝·모니터링 필요 | 클러스터 설정·모니터링·백업·보안 설정 필요 | 운영 복잡도·운영 비용↑ |
| 비용 | 추가 인프라 불필요 | 앱 서버 메모리 사용량 증가 | 전용 캐시 서버(또는 매니지드) 사용으로 안정적 | 서버·네트워크 비용 발생 |
gpt 선생님이 이렇게 답변을 해주셨는데 좀 정리하자면
로컬 캐시 : 빠른데 용량 크게 설정 x
분산 캐시 : 로컬보단 느리지만 용량 크게 O
실제로 로컬 캐시는 세팅하기가 매우 쉽다. 레디스도 어려운편은 아니지만 로컬 캐시보단 세팅할게 좀 있다.
우선 캐시를 도입해도 되는지?
우리 서비스에서 캐시를 사용해도 되는지의 판단 여부는 학과 소개, 교수 목록, 교과목 목록 등 자주 변화하지 않는 데이터에 많은 조회가 발생하기에 적합하다고 생각했다.
그런데 왜 현재 진행중인 홈페이지 프로젝트에 로컬 캐시를 도입했을까?
2가지 이유가 있는데
첫번째는 압도적인 성능 때문이다. 외부의 네트워크를 사용하지 않고 Caffeine Cache인 경우 JVM내에서 작동하기에 외부 로컬 캐시보다 압도적으로 성능이 빠를 수 밖에 없다.
두번째는 의존성 감소다. 만약 우리가 레디스를 캐시서버로 사용하고 있다고 가정해보자. 갑자기 레디스 서버가 꺼지게 된다면 우리는 그대로 데이터베이스에 직접적인 부하가 쏠릴수 밖에 없을 것이다.
마지막은 단일 인스턴스 환경이었기 때문이다. 데이터의 일관성을 크게 신경쓰지 않아도 괜찮았기 때문이다.
자 이제 만약 분산 환경이라면 로컬 캐시를 어떻게 도입해야될까??
그냥 도입하면 되는거아님?이라고 생각하면 하수인 생각이다.
사실 캐시에서 가장 크게 고려해야될 요소는 데이터의 일관성이다. 만약 캐시 A가 변경되고 B에 변경사항이 적용되지 않으면 각 사용자마다 다른 내용을 볼 수 있기 때문이다. 이전까지는 단일 인스턴스여서 그런 상황을 생각안해도 됐지만 여러 인스턴스일 경우 가장 신경써서 고려해야되는 요소다.
쨋든 로컬 캐시의 데이터의 일관성을 어떤 방식으로 고려해야할까?
첫번째 캐시의 TTL을 세팅하는 것이다. 뭐 당연한 소리겠지만 이 방법으로는 데이터의 완벽한 일관성을 맞추지 못한다. TTL을 짧게 둘 수록 캐시의 의미는 없어질뿐만 아니라 데이터베이스에 지속적인 부하가 쏠리기 때문이다.
두번째는 이벤트-드리븐 전략이다. 쓰기 시 메시지 브로커에게 키 무효화 이벤트를 발행해 각 인스턴스가 구독해서 evict를 시켜주는 과정으로 기업에서 많이 쓰는 전략인듯 하다 아래 게시글이 도움이 많이 되었다.
https://tech.kakaopay.com/post/local-caching-in-distributed-systems/
분산 시스템에서 로컬 캐시 활용하기 | 카카오페이 기술 블로그
분산 시스템에서 로컬 캐시를 설계하고 구현한 경험을 공유합니다.
tech.kakaopay.com
나머지는 버전태깅, 폴링 방식이 있는데 이런 방식은 결국엔 지속적으로 TTL을 통해 통신하는 방법이니 패스하겠다.
또 공부해보면 도움되는 내용이 http cache-controll 을 공부해보면 도움이 많이 될 것 같다.
https://toss.tech/article/smart-web-service-cache
웹 서비스 캐시 똑똑하게 다루기
웹 성능을 위해 꼭 필요한 캐시, 제대로 설정하기 쉽지 않습니다. 토스 프론트엔드 챕터에서 올바르게 캐시를 설정하기 위한 노하우를 공유합니다.
toss.tech
그 다음으로 분산 캐시를 분산 환경에서 적용하기는 로컬캐시보다 훨씬 쉽다
어차피 외부에 캐시가 있기때문에 여러 인스턴스 환경에도 글로벌 캐시에 접근하면 되기 때문에 데이터의 일관성을 지키기 쉽다. 그런데 글로벌 캐시에 엄청나게 많은 부하가 걸린다면??

답은 쉽다. 그냥 Redis Cluster/Sentinel 기능 활용해서 레디스를 확장하면 쉬워진다.
특히 Cluster은 샤딩으로 Scale-out이 가능하여 캐시의 분산처리도 용이하게 할 수 있다.
그래서 요새는 분산락, 스케일아웃가능, 데이터 일관성 같은 문제로 인하여 큰 규모의 회사에서는 Redis를 많이 도입하는 것 같다.
'Project' 카테고리의 다른 글
| K6 & Grafana를 활용하여 병목 해결 & 스레드풀, 커넥션풀 조절기 (0) | 2026.05.11 |
|---|---|
| [Project] 인스턴스 서버에 너무 많은 부하가 쏠리다면? (0) | 2025.04.17 |
| [Project] 적절한 풀 사이즈 설정하기 (1) | 2025.03.26 |
| [Project] Spring 직렬화, 역직렬화 문제 - getWriter() has already been called for this response (1) | 2025.02.28 |
| [Project] 게시물 N+1 문제 해결기 (쿼리 40 -> 11 -> 1) (0) | 2025.01.31 |



